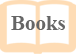If you were a teacher of English, are you confident in
teaching/instructing English as a foreign language (EFL) listening ?
Would you like to know how to instruct where comprehension
breaks down and why precisely?
You’d be more confident in EFL listening instruction by understanding
why and where comprehension fails.
- Top
- for teachers
Two Fundamental Theories for Instructing EFL Listening
Here, two fundamental theories of the Ueda Methods (the effective methods of instruction and learning for EFL learners based on two theories, both of language understanding and human information processing, and also based on statistical data and its analysis) are introduced.
❶ Cognitive Psychology Theory Anderson (2010)
Anderson (2010) claims that language learning involves certain steps and proposes a cognitive framework of language comprehension based on perception, parsing and utilisation. Although these three phases are interrelated, recursive and possibly concurrent, they differ from one another. At the lowest cognitive level of listening, perception is the decoding of acoustic input that involves extracting phonemes from a continuous stream of speech.
 Perception
Perception
With regard to the first stage, Anderson (2010) argues that there are at least two problems in speech perception or recognition, i.e. segmentation and co-articulation. The first problem, segmentation, occurs when the phonemes need to be identified, but unlike printed text, speech is not broken into discrete units. Speech is a continuous stream of sounds with no noticeable word boundaries. Thus, any new learner of English normally experiences this problem. Anderson defines phonemes as the minimal units of speech that can result in a difference in the spoken message (p. 51). Words are divided into two categories, i.e. content and function words. Nouns, verbs, adjectives, adverbs and demonstrative pronouns are categorised as content words (Gimson, 1980, p. 256); they convey relevant information unlike function words such as prepositions, conjunctions and determiners. Thus, function words are not generally stressed in listening. Furthermore, the segmentation problem and unstressed words are firmly related. Examples of the segmentation problem include assimilation, contraction, deletion, elision, liaison/linking and reduction (Yoshida, 2002, p. 32).
According to Ladefoged (1982, p. 99), assimilation occurs when one sound is changed into another because of the influence of a neighbouring sound (e.g. ‘Red Cross’ can be heard as /reg kros/ and ‘hot pie’ as /hop pai/).
Contraction is defined as a vowel-less weak form by Knowles (1987, p. 146). Examples of contractions in sentences, especially in rapid speech, include ‘going to’ which becomes ‘gonna’, as in ‘I’m gonna do it tomorrow’; ‘got to’, which becomes ‘gotta’, as in ‘I’ve gotta go’ and ‘I would’, which becomes ‘I’d’, as in ‘I’d say so’.
Deletion is the removal of a part of the pronunciation. For example, in rapid speech, ‘because’ becomes ‘cuz’, as in ‘I’m studying English cuz I’m going abroad’, and ‘them’ becomes ‘em’, as in ‘Why don’t you go with em?’
Rost and Wilson (2013, p. 305) use ‘elided’ to describe elision, which is defined as the omission of sounds in rapid connected speech. They also state that this is usually the result of one word ‘sliding’ into another, and the sound omitted is usually an initial or final sound in a word (e.g. ‘soft pillow’ can be heard as /sof pilow/ and ‘old man’ as /oul man/).’
According to Cutler (2012), liaison is ‘a final sound pronounced only when the following word begins with a vowel…it interacts with segmentation of the speech stream’ (p. 206). Examples include ‘I’ll need to think about it’, ‘The sheep licked up the milk’ and ‘Not at all’.
Finally, as an example of reduction, which reduces the number of vowels that occur in unaccented syllables (Knowles, 1987, p. 97), Yoshida (2002) introduces a sentence such as ‘You dropped your handkerchief’ in which the word ‘your’ is not stressed (p. 32). This phenomenon occurs because the word ‘your’ is a function word and is unstressed.
The second problem in speech perception involves a phenomenon known as co-articulation (Liberman, 1970). Ladefoged (1982, p. 52) defines co-articulation as the overlapping of adjacent articulations; that is, as the vocal tract is producing one sound, it moves towards the shape for the following phoneme. For example, the sound of /b/ itself and the /b/ in ‘bag’ are different. Thus, when pronouncing /b/ in ‘bag’, the vocal tract is already moving towards the next sound /a/. In addition, when pronouncing /a/ in ‘bag’, the root of our tongue is raised to produce the /g/. These segmentation problems pose complications for any learner of English, since an independent phenomenon of segmentation does not usually occur in a single sentence. Rather multiple phenomena of segmentation might occur in just a single sentence. Moreover, these difficulties exist only in perception, the lowest cognitive level of listening. Anderson (2010, p. 52) describes that speech perception poses information-processing demands that are, in many ways, greater than what is involved in other types of auditory perception.
Many Japanese learners of English encounter these segmentation problems. Ikemura (2003) indicates that the auditory recognition of words is one of the major problems at the speech perception level for Japanese learners of English. This is because reading and writing are generally emphasised at schools in Japan; this is evidenced by the fact that it was only since 2006 when a listening comprehension test was introduced in the national examination of Japanese universities.
 Parsing
Parsing
Next, the second stage in Anderson’s cognitive psychology theory (2010) is parsing. In parsing, words are transformed into a mental representation of the combined meaning of the words. This occurs when a listener segments an utterance according to syntactic structures or meaning cues. According to Anderson (2010), people use the syntactic cues of word order and inflection to interpret a sentence (p. 366). Thus, when a sentence is presented both with and without a major constituent boundary, it is more difficult to comprehend the latter form.
 Utilisation
Utilisation
The third and final stage is utilisation. In this stage, it is sometimes necessary for a listener to make different types of inferences to complete an interpretation of an utterance, especially since the actual meaning of an utterance is not always the same as what is stated. That is, to completely understand a sentence, a listener sometimes needs to make inferences and connections so that s/he can make the sentence more meaningful. In addition, mental representation is also required to comprehend the speaker’s actual meaning.
❷ Controlled and Automatic Human Information Processing Schneider and Shiffrin (1977)
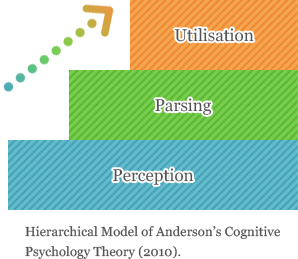
Schneider and Shiffrin (1977) propose that learning includes two types of cognitive processing, i.e. controlled and automatic human information processing. Controlled processing involves a sequence of cognitive activities under active control which draw the conscious attention of the subject.
Conversely, automatic processing involves a sequence of cognitive activities that automatically occur without active control and generally without conscious attention. This theory is supported by numerous studies (Lynch, 1998; Goh, 2000; Buck, 2001; Anderson, 2010). Buck (2001) adeptly illustrates both types of processing by comparing them to the scenario of learning to drive a car.
In this regard, initially, the entire learning process is controlled, thus requiring conscious attention to every action. After more experience, certain parts of the process become relatively automatic and are performed subconsciously. Eventually, the entire process becomes automatic to the extent that, under normal circumstances, one has the ability to drive a car well and without much thought. The figure shown above demonstrates the hierarchical model of controlled and automatic human information processing, following Schneider and Shiffrin (1977).
Based on this theory, dictation in listening is categorised as controlled processing (bottom-up processing) since it involves phonemic decoding, which requires conscious attention to phonemes, the smallest segments of sound (Ladefoged, 1982). In contrast, from a listening strategy perspective, the identification of individual words is mainly regarded as automatic processing (top-down processing), because it can only be possible after phonemic decoding occurs automatically without active control and conscious attention.
Thus, the less automatic an activity becomes, the more time and cognitive energy it requires. In this regard, when learners take more time in phonemic decoding, their overall comprehension suffers.
上記の2つの理論に基づいてリスニング中位層学習者を対象に実験を行ったところ、最下層の音素の識別を繰り返し行うことで
徐々に意識しなくてもできるようになると、文法的区切れを意識する余裕が生まれ、
同様に、文法的区切れを自動化することができると、話者の意図理解に集中することができるということが実証されました。
そこで、上田メソッドを適応させることができるかを把握するため、まずは学習者が中位層学習者に該当するかを測定しましょう。
まずは学習者のリスニング能力を測定・把握しましょう
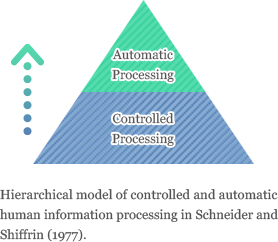
Firstly, it’s vital to ascertain learners’ listening comprehension ability with any standardised test (i.e. the TOEIC®, the TOEFL®, IELTS, Cambridge, EIKEN, etc.). In order to apply the Ueda Methods, learners need to be at the Intermediate level.
TOEFL®/TOEFL iBT®/IELTS/EIKEN/Cambridge (CPE、CAE、FCE、PET、KET)/TOEIC®
The TOEFL iBT® test measures the ability to use and understand English at the university level, i.e. listening, reading, speaking and writing skills for academic tasks. The International English Language Testing System (IELTS) is designed to assess the language ability of candidates who seek to study or work where English is the primary language of communication. The IELTS is accepted by thousands of organisations in more than 135 countries. Cambridge = Cambridge English Language Assessment, CPE = Certificate in Proficiency in English, CAE = Certificate in Advanced English, FCE = First Certificate in English, PET = Preliminary English Test, KET = Key English Test and EIKEN = a test in practical English proficiency, which is Japan’s most widely recognised English language assessment.
At the same time, it’s vital to ascertain learners’ metacognitive awareness in EFL English with the MALQ.
Failure Analysis: How to Find Precisely Where Learners’ Comprehension Fails
認知心理学理論の3段階 (話者の意図理解、文法的区切れ、音素の識別) で、学習者がどの段階で理解できなくなってしまったのかを
明らかにすることで段階に応じた診断的で具体的な指導ができます。
 「音素の識別」でのつまずきかどうか診断する方法と指導法
「音素の識別」でのつまずきかどうか診断する方法と指導法
診断方法
ディクテーション (音声を文字にする作業) をさせる
Procedures #1
Explain that words can be divided into two groups: (1) Content words and (2) Function words. The purpose of this is so that learners can know that they do not need to catch every single word and so that they can relax when listening in English. Knowing many people are not familiar with Content and Function words, this knowledge is vital to improving EFL listening comprehension ability effectiveness.
Content words
The definition of Content words in this site is “the words which are vital to understanding what is spoken”.
Furthermore, the following are the five elements of Content words in this site.
- Nouns
- Verbs
- Adjectives
- Adverbs
- 5W1H (who, when, where, what, why, how)
Function words
The definition of Function words in this site is “the words which are not necessarily vital to understand what is spoken.” Also, the elements of Function words in this site are words which are not Content words, such as articles and prepositions.
i.e.) Father Coma Immediately Back Home
The above is a classic example of a telegram in Japan many years ago. However, people usually do not speak like this. “Our father is in a coma. So, come back home immediately,” would be more natural to say.
Telegrams were charged based on the number of letters to be sent, so words which are not vital to understanding used to be omitted. And thus, a telegram like “Father Coma Immediately Back Home” used to be sent. Although we do not possess the knowledge about Content and Function words, we naturally know which words are vitally correlated with understanding. Every language has Content and Function words, this knowledge can be applied into any language. By instructing that it is not necessary to listen to every single word for comprehending what is spoken, we can reduce a certain degree of pressure on learners in EFL listening.
Procedures #2
Ask your students to dictate the parts which are critical to answer correctly. You may adjust the range to dictate depending on the level of the students or time limit. For example, when the level of the students is low or when time is limited, let the students dictate up until the dotted line in the example below. As for the number of chances to listen, make sure that the maximum is five times based on the study of Hori (2007, p.102).
Hori, T. (2007). Exploring Shadowing as a Method of English Pronunciation Training. Unpublished doctoral dissertation. Kwansei Gakuin University, Japan.
i.e.) The answer is (A). These grey parts are the vital content words for the correct answer.
the other important content words
1. Where is this conversation taking place?
(A) In an office
(B) In an airplane
(C) At a school office
(D) On a train platform
Man:What did you do with the customer record I gave you about an hour ago?
They were on my desk earlier this morning.
—————— (Dictating up to this line depends on the level of the students or available time) —————–
Woman:Oh, I took them to the copy room and copied them. I put them back on your desk.
Man:Oh, good. I thought you might have sent them to our customers. I still need to make some changes before I take them to the post office.
(Stafford, 2009, p.7)
Procedures #3
When dictation is finished, provide the audio script and ask the learners to highlight the content words that they could not catch when listening.
![]()
正答するために必要内容語が聞き取れていなかった場合、音素の識別でつまづいていることがわかる!
Until your students fully understand which words are the Content words in the listening exercise, be sure to check their individual audio scripts for whether they correctly highlighted only Content words.
Instructions
Procedures #1
Ask your students to circle the Content words in read which they cannot understand even when reading the audio script.
Then, let them check the part of speech and definition of each word.
→The cause of incomprehension is insufficient vocabulary.
Procedures #2
Combination of Both Acoustic Information and Information with Letters
For many learners of English in Japan, when reading, the information is processed with meanings.
However, when the same information is given only acoustically, there is much less chance that it is processed with meanings. This indicates that there is imbalance between ability to process information with sounds and ability to process information provided with letters. Thus, a training regimen which fills the gap is necessary (i.e. To listen to the English at least three times by looking at its audio script which contains the content words that the learner could not comprehend during listening).
Procedures #3
Improvement of an Ability to Process the Information Acoustically
In order to comprehend the information just by listening without reading its audio script, training to listen to the English at least three times without looking at the audio script is recommended.
It is important to ask your students to keep their eyes open whilst doing this training. In my experience, I have observed that many students slept during this procedure, though it is not guaranteed that those who with open eyes during the training regimen were concentrating.
Procedures #4
Finally, ask your students to listen to the English at least three times without looking at the audio script which contains the content words that the student could not comprehend. Also, ask your students to repeat this procedure at home.
 「文法的区切れ」でのつまずきかどうか診断する方法と指導法
「文法的区切れ」でのつまずきかどうか診断する方法と指導法
診断方法
You may ask your students to do the following procedure when they could dictate all the necessary content words to answer correctly yet they still got the wrong answer.
Ask your students to insert forward slashes
where they think there are Constituent Structure on what they have just dictated.
Language is structures according to a set of rules that tell us how to go from a particular string of words to an interpretation of that string’s meaning…In learning to comprehended a language, we acquire a great many rules that encode the various linguistics patterns in language and relate these patterns to meaningful interpretations…Although we have not learned to interpret all possible full-sentence patterns, we have learned to interpret subpatterns, or phrases, of these sentences and to combine, or concatenate, the interpretations of these subpatterns. These phrase units are also refereed to as constituents. (Anderson, 2010, p.360)
![]()
誤った箇所に斜線が挿入されている場合、文法的区切れでつまづいていることがわかる!
Instructions
Then, check whether the students put the slashes into the correct grammatical boundaries. If not, instruct where the correct grammatical boundaries.
For example, Graff and Torrey (1966) present the importance of identifying constituent structure as follows:


In Form A, each line corresponds to a major constituent boundary unlike the lines in Form B. In the study by Graff and Torrey (1966), the participants presented with Form A (with its correct syntactic structures) showed better comprehension of the passages. This finding proves that the identification of constituent structure is vital to comprehension. When one reads passages, it is natural to pause at the boundaries between clauses. These passages or segments with correct syntactic structures are then recombined to generate a meaningful representation of the original sequence. The importance of ‘parsing a sentence’ or constituent structure is also confirmed by Jarvella (1971), Caplan (1972) and Aaronson and Scarborough (1977). As for the characteristic of parsing, Anderson (2010, p. 362) describes that people process the meaning of a sentence one phrase at a time and maintain access to a phrase only while processing its meaning. He refers to this principle as ‘immediacy of interpretation’. In other words, people, when processing a sentence, attempt to extract meaning out of each word as it arrives, and they do not wait until the end of a sentence or even the end of a phrase to decide how to interrupt a word.
As for Japanese learners of English, where learners’ comprehension typically fails is at the Perception level. Thus, it is quite rare that you need to instruct at the Parsing level.
 「話者の意図理解」でのつまずきかどうか診断する方法と指導法
「話者の意図理解」でのつまずきかどうか診断する方法と指導法
診断方法
You may ask your students the following procedure when they could dictate all the necessary content words to answer correctly and also insert the slashes correctly at grammatical boundaries, yet they still got the wrong answer.
Ask your students to translate the sentence (s) into Japanese focusing on what the speaker really means.
![]()
「意訳」が正しくない場合、話者の意図理解でつまづいていることがわかる!
Instructions
In case the translation is not what the speaker really meant, correct and instruct it by providing necessary cultural background knowledge, context about where and who the listener and the speaker are, and so on.
Example 1) Were you born in a barn?
For example, in England, a sentence such as ‘Were you born in a barn?’ does not actually enquire whether the listener was born in a barn. Instead, it infers that if a person was born in a barn, then s/he is unaware of the custom of closing a door after entering/exiting a building.

Thus, the actual and ironical meaning of the sentence is ‘Shut the door!’ Successful comprehension requires a finishing touch, called utilisation, after the perception and parsing stages.
Example 2) an example which comprehension fails at the utilisation level in Japanese
At a teachers’ meeting at the end of March…
Teacher A: On which day does April start?
Teacher B: On the 1st.
Actually, Teacher B was me. When I was asked this question, I was wondering what a strange question to ask since every single month’s start is, of course, on the 1st. But within a 0.1 second, I thought “OMG!” realising what Teacher A really meant. Of course, it was too late. What Teacher A really meant was “On which day, a new term will start?” but because I did not have enough ability to infer, I failed to understand what Teacher A really meant. This is a typical example where comprehension ability ends at the Utilisation Level. Teacher A became speechless for a moment with my stupid reply. In this way, there are always risks where comprehension ability ends at the Utilisation Level in any languages.
上田メソッドの科学的根拠
●過去の研究からリスニング・ストラテジーについて明らかになっていること
認知心理学におけるAnderson (2010) の言語理解に関する理論では、
最下層からperception(音素の識別)、parsing (文法的区切れ)、Utilisation (話者の意図理解)と
三段階あり、相互関係にあるとされている。
Based on Anderson’s theory, O’Malley et al. (1989) conducted a milestone study on listening strategy with 11 Hispanic intermediate students. They revealed that the mental processes of the students in listening comprehension actually parallel Anderson’s (2010) cognitive psychology theory in four ways:
- the students were listening for larger chunks, shifting their attention to individual words only when there was a breakdown in comprehension;
- they utilised both top-down and bottom-up processing strategies, whereas ineffective listeners repeatedly attempted to determine the meanings of individual words;
- they were adept at constructing meaningful sentences from the input received, even though the meaning slightly differed from that of the actual text and
- they applied their knowledge in three areas, i.e. world knowledge, personal knowledge and self-questioning.
Differences in the listening strategies by proficiency levels
-Skilled listeners report an automatic flow of the auditory stimulus, and they apply keywords, inferences and grammar strategies, whereas less-skilled listeners use keywords and translation strategies as well as contextual inferences DeFilippis (1980). He also reports that skilled listeners utilise five times more visualisation, three times more French?English cognates and two times more role identification compared to their less-skilled counterparts. His study is followed by numerous researchers in the 1980s such as Murphy (1985), Chamot (1987), Murphy (1987), O’Malley (1987), Rubin (1988), Rubin, Quinn and Enos(1988) and O’Malley, Chamot and Kupper (1989), Hamamoto et al. (2013), Ueda (2015),
-Ho (2006, p. 71) is consistent with the study by DeFilippis (1980) in which low-proficiency listeners significantly use the translation strategy more often than high-proficiency ones.
– Differences between More- and Less-Proficient Listeners (Berne, 2004, p. 525)
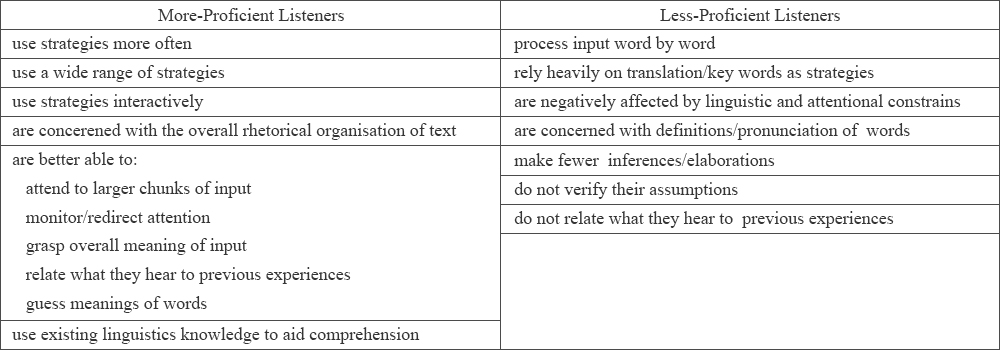
Differences in kinds and numbers of the listening strategies and knowledge when to use by proficiency levels
-Goss (1982) reports that competent listeners are capable of using many strategies and knowledge when to use them. Murphy (1985) also presents a different feature between more- and less-proficient listeners. The former tend to use a strategy called ‘wide distribution’ (an open and flexible use of strategies), whereas the latter frequently use a ‘text heavy’ strategy (which depends on the text and the consistent paraphrasing).
-O’Malley et al. (1989) observe that effective listeners utilise both top-down and bottom-up processing strategies, whereas ineffective listeners become embedded in determining the meanings of individual words (p. 434).
They also report that effective listeners notice when their attention falters and they make a deliberate effort to refocus on the listening task, whereas less-effective listeners encounter an unfamiliar word and make no effort to continue listening.
Differences in metacognition ability regarding listening strategies by proficiency levels
-Other significant differences between effective and ineffective listeners are also observed with regard to self-monitoring (or checking one’s listening compre hension), elaboration (or correlating new information with prior knowledge or other ideas) and inference (or using information in a text to guess the meaning or complete the missing ideas) (O’Malley et al., 1989, p. 427).
-Graham, Santos and Vanderplank (2011) confirm that the use of metacognitive strategies increases with higher listening proficiency and that both inferencing and reliance on prior knowledge appear to become less prominent as learners’ listening proficiency increases.
These results match the studies of Graham et al. (2008), Vogley (1995) and Vandergrift (1997, 1998).
-Hamamoto et al. (2013) report that the intermediate listeners show tendencies similar to the high-level listeners in the use of advanced organisation and self-management of metacognitive strategies, whereas they were similar to the low-level listeners in inferencing.
Metacognitive knowledge and its usage is the key to become a successful listener.
Metacognitive knowledge and its usage is the key to become a successful listener.
DeFilippis (1980), O’Malley, Chamot and Kupper (1989), Goh (1997, 2002) and Vandergrift (2003),Baleghizadeh and Rahimi (2011), Ueda (2015)
Flavell (1979, p. 906) defines metacognitive knowledge as ‘that segment of stored world knowledge that has to do with people as cognitive creatures and with their diverse cognitive tasks, goals, actions, and experiences’.
-Goh et al. (2006) introduce a concrete metacognitive knowledge about listening.
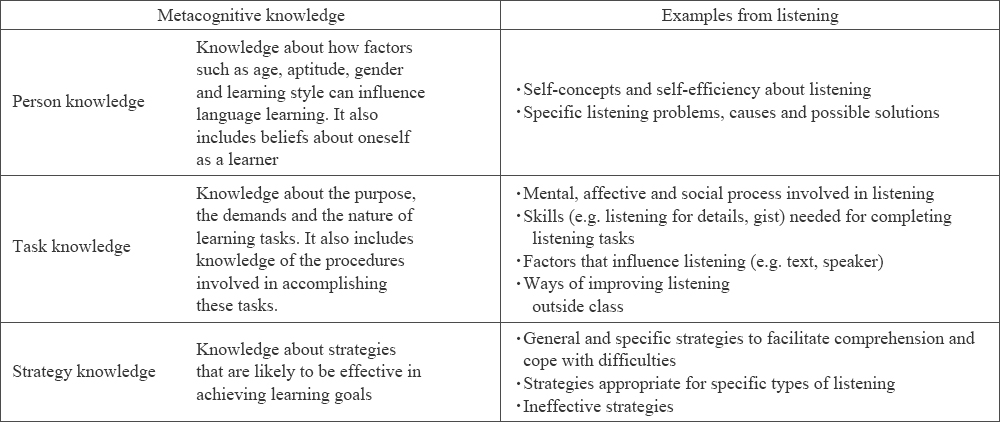
-Chamot (1995, p. 18) describes that the failure of less-effective listeners to use appropriate strategies for the different phases of listening is due to limited metacognitive know
-Vandergrift, Goh, Mareschal and Tafaghodtari (2006) conduct a survey regarding metacognitive awareness in listening by administering the MALQ. They establish the following five factors based on the responses of 966 participants: 1) problem solving (guessing as well as monitoring the guesses), 2) planning and evaluation (preparing to listen and assessing success), 3) mental translation (translation from English to first language (L1) when listening), 4) person knowledge (confidence or anxiety and self-perception as a listener) and 5) directed attention (ways of concentrating on certain aspects of a task). These factors, which accounted for approximately 13% of the validity in the listeners’ performance, suggest that approximately 90% of success in listening is based on additional factors. This also indicates the complexity of listening comprehension in English.
Lynch (2009, pp. 82?83) claims that this finding is the most tangible outcome from two decades of research regarding metacognitive strategies in listening.
リスニング・ストラテジーについて過去の研究では、まだ明らかになっていないこと
- 上位層が用いているリスニング・ストラテジーを下位層に指導することは可能であり、習熟度も向上するということ。